

MySQL, sans être une révolution technique en soi, rentre à mes yeux dans le modèle de disruptive innovation décrit par Clayton Christensen dans son livre The Innovator’s Dilemma.
En particulier, MySQL a grandi dans les années 2000 en surfant sur la vague des sites dynamiques auxquels besoins il répondait parfaitement avec un serveur à la fois gratuit et allégé en terme de fonctionnalités mais couvrant finalement la majorité des besoins de ces sites (point B). MySQL s’était engouffré dans le vide laissé par les sociétés comme Oracle, au serveur couteux et compliqué, dont seule une petite partie des utilisateurs exploite la majorité des fonctionnalités.

Pour rappel, toute l’analyse de Christensen est basé sur le volume de fonctionnalité. Ce que couvre l’innovation de disruption (courbe violette) est toujours faible (point B) mais croît plus vite que la demande globale du marché (courbe orange), elle même largement surpassée par ce que propose les leaders (courbe verte).
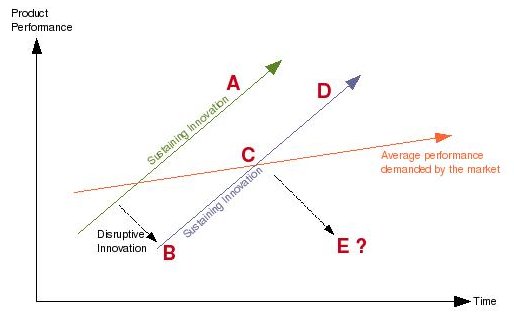
Comme j’expliquais fin 2005, le jeu s’arrête quand l’innovateur croise la courbe du marché (point C), qu’il innonde alors. Les leaders, la plupart du temps, partent dans une fuite en avant consistant à augmenter leurs fonctionnalités (point A), réduisant de plus en plus la taille de leur clientèle pleinement satisfaite du ratio «coût global» sur «fonctionnalités réellement utilisées».
Pour MySQL, le jeu de l’innovateur s’est plus ou moins arrêté lors du rachat par Sun, preuve de la position incontournable acquise sur le marché. Mais non seulement MySQL a désormais croisé la courbe du marché, mais il semble devenir petit à petit une courbe de leader (point D), nettement au dessus de la demande globale du marché.
C’est du moins ce que certains professionnels commencent à dire, expliquant qu’un maintien de la version 4.1 ou 5.0 suffit largement à couvrir les besoins des professionnels du Web, et que la version 6 n’apportera surement rien à la majorité des utilisateurs.
On retrouve donc le même symptome de glissement vers le haut du marché pour répondre à la demande toujours grandissante d’un petit nombre d’utilisateur, au prix d’un accroissement de la complexité d’utilisation pour la majorité des utilisateurs.
MySQL, le disruptor devenant disruptee ?
Alors, MySQL qui se retrouve petit à petit dans la position de leader, prend-il le risque de voir à son tour apparaître une innovation de rupture (point E) venant mettre à mal à moyen terme sa position ? Je ne suis pas vraiment certain en fait, pour deux raisons.
La première, c’est la disponibilité MySQL en open source. Dans le modèle théorique de Christensen, la fuite vers le haut du marché engendre une complexification du produit et donc un accroissement de son coût, qui ne fait qu’accélérer à nouveau la fuite vers une clientèle réduite. MySQL étant gratuit, le problème ne se pose pas. Même si la complexification de MySQL engendre sûrement un besoin (et donc des frais) en conseil ou intégration, j’ai le sentiment que la majorité des utilisateurs peut utiliser MySQL sans ce surcoût, qui ne concerne (mais je me trompe peut-être) que les utilisateurs exploitant au maximum le logiciel.
La seconde, c’est l’état de l’art de la profession. Les besoins en terme de base de données pour le développement Web ont tout de même nettement évolué depuis les années 2000, et le développement Web s’est professionnalisé petit à petit. Tant côté client (démocratisation des bonnes pratiques du W3C entre autre) que côté serveur avec l’évolution des pratiques PHP (usage croissant des moteurs de template, solution de cache et abstraction de base de données vers 2002, puis des frameworks de développement vers 2005). L’usage de MySQL s’est sûrement lui aussi professionalisé petit à petit.
Si il y a innovation disruptive, ce ne sera sûrement pas par une version simplifiée comme l’était à l’époque MySQL vis-à-vis des serveurs comme Oracle, mais probablement plus par une innovation purement technologique dans le domaine des bases de données relationnelles.
Le modèle de Christensen laisse cela dit suggérer qu’il y a petit à petit la place (point E) pour une innovation sur ce marché. À suivre dans les années à venir…
Vincent
Même raisonnement pour PHP alors ? 🙂
Guillaume Mouron
Marrant que tu fasses cet article le jour ou le co-fondateur de MySQL annonce son depart.
Ensuite, je crois que ta vision de la professionalisation de MySQL/PHP est biaisee. Non pas qu’elle n’existe pas, mais a mon sens, il y a encore beaucoup beaucoup beaucoup de gens qui font du PHP/MySQL sans cette "professionalisation" et pour qui moteur de template ou cache ne veut rien dire.
Olivier
Concernant la professionnalisation, je pense qu’il y a des signes qui ne trompent pas. Notamment au niveau recrutement, il y a 2 ans très peu de candidats savaient ce qu’était en framework de développement, ou bien répondait que oui, ils utilisaient le Zend Studio… Nous avions à les former à ce type d’outil.
Depuis un an, je t’assure qu’il y a une vraie tendance à la hausse sur les candidats ayant déjà des expériences de framework, notamment grâce à l’effort marketing de Zend pour promouvoir son Zend Framework auprès des agences Web et SSII.
Vincent, je ne suis pas sur que ce soit applicable dans le cas des langages de programmation. De toute façon, PHP a gagné 🙂
Nicolas
(J’arrive un peu après la bataille…)
Il me semble que tu a loupé un point important sur ce sujet, qui mériterait presque d’être la conclusion de cet article.
Si on considère ta flèche verte comme la progression d’Oracle, et ta flèche bleue comme celle de MySQL, alors l’évènement B est le lancement de MySQL, et l’évènement E est le lancement de Drizzle (https://launchpad.net/drizzle).
Drizzle est un SGBDR basé sur MySQL 6, avec un maximum de fonctionnalités « lourdes » supprimées : pas de vues, pas de procédures stockées, pas de triggers, pas de cache de requêtes, pas de grants… Sur Equideow, on fait autour de 150-200 millions de requêtes SQL par jour. Qu’est-ce qui se passerait si on arrêtait de vérifier un couple login+password pour toutes ces requêtes ? Drizzle a pour but de simplifier l’utilisation d’une base de données relationnelle et d’accélérer les requêtes dans le cas d’applications web (c’est « orienté cloud », si ça veut dire quelque chose…).
Cela montre la réactivité de MySQL, qui a su écouter ses utilisateurs pour leur fournir ce dont ils ont besoin. Le projet est parallèle à MySQL 6, qui reste disponible pour les gros clients. Cela dit, le projet n’est pas encore prêt.
Un autre point qui aurait pu apparaître en E, c’est l’émergence des bases de données non relationnelles. Des grands acteurs s’y mettent, avec par exemple Google qui a ouvert un accès à BigTable sur son App Engine, Amazon qui a lancé SimpleDB, et la progression des datastores temporaires comme Memcache. Il y a également une grosse hype autour de CouchDB, qui est non-relationnel et schema-less (pas le même nombre de colonnes pour chaque entrée). Ces bases sont très rapides, et suffisent dans bien des cas (en fait, à chaque fois qu’une sélection par ID suffit). L’entrée de grosses entreprises sur ce marché et en particulier dans le business des applis dans le cloud (App Engine, EC2) montre l’intérêt que suscitent ces technologies.
On pourrait presque dire que le modèle LAMP est web 1, avec chacun son petit serveur et du code sans framework, tandis que la tendance actuelle est à la migration d’applis vers un lieu indéterminé (le cloud), soutenues par de nouvelles techniques de stockage (que ce soit pour les données dans SimpleDB ou les médias dans S3). Ça s’appelle comment ? Web 2.1 ? 🙂
L’omniprésence de Memcache sur les sites à forte charge montre qu’il est possible d’organiser ces données selon un modèle clé ? valeur, même dans le cas de structures complexes : Facebook a publié le chiffre de 1800 serveurs Memcache.
Les alternatives sont déjà là, et MySQL est au courant. Il est fort possible que Drizzle soit une réponse aux SGBDNR, permettant de maintenir la compatibilité avec les applis existantes. Comme toujours, il faut choisir le bon outil ! À l’heure actuelle, MySQL n’est pas ce qu’il se fait de mieux pour stocker des paires (clé, valeur).
Comme souvent, la compétition promet d’amener de l’innovation 🙂
Olivier
Effectivement, c’est un oubli important pour Drizzle. Voilà donc une réponse possible pour le point E 🙂
Mais je pense pas que cela suffit. Je veux dire, si Drizzle est juste une simplification, ce n’est pas disruptif en soi je pense. MySQL était une simplification, mais ce qui était en rupture était le modèle économique (serveur gratuit et libre).
Le potentiel "disruptor" c’est plutôt comme tu le soulignes le stockage dans le "cloud", qui pour le coup change la donne sur de nombreux aspects : modèle économique, accès, modèle de stockage plus adapté aux besoins, etc… Reste à voir si ces nouvelles formes de stockage atteindront le marché de masse ou resteront confinés aux utilisateurs avertis.
Stéphane Le Solliec
Dès que les gens auront un peu joué avec les applications web sémantiques, (genre dbpedia, foaf, etc …) le besoin d’entrepôts RDF requêtables en SPARQL va être énorme.
IMHO, la prochaine innovation c’est ça, et c’est là dessus que devraient s’axer les développeurs de SGBD actuellement.